I got to this point and felt surprised...
Quote:
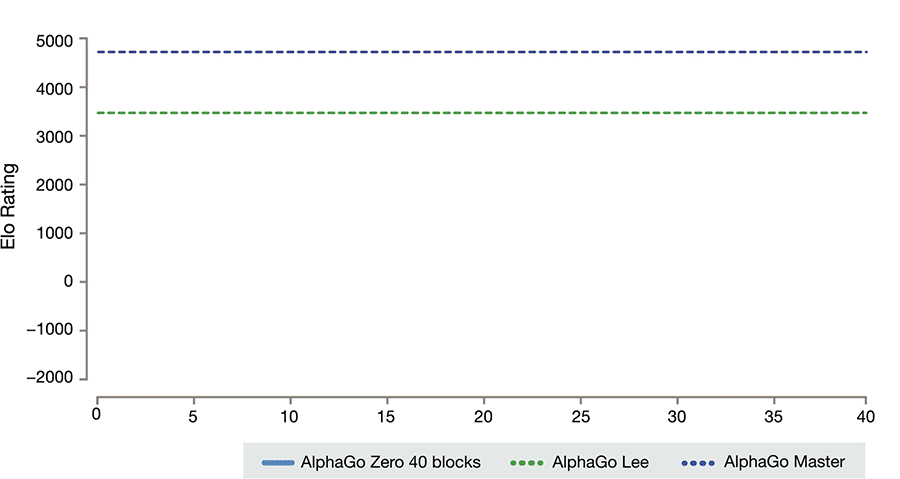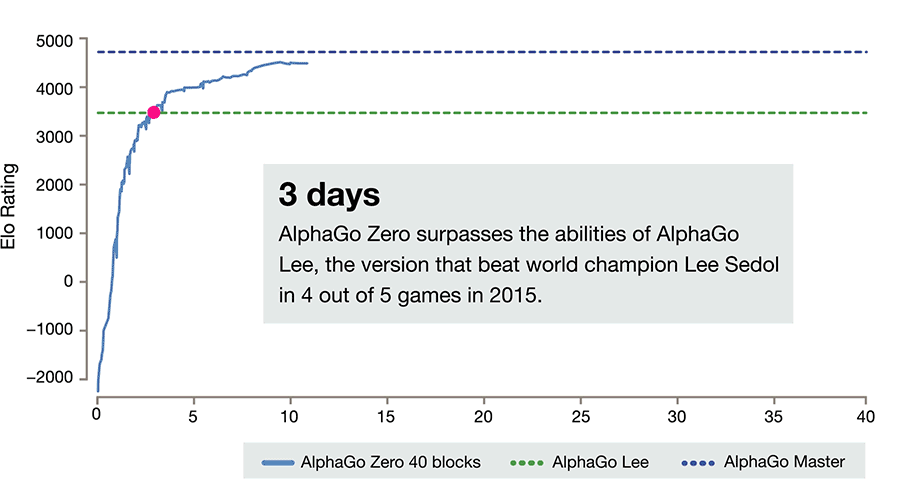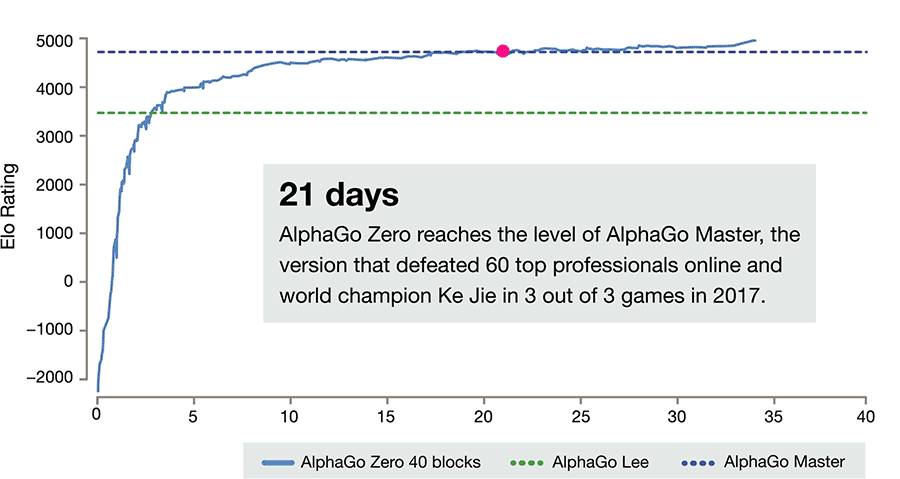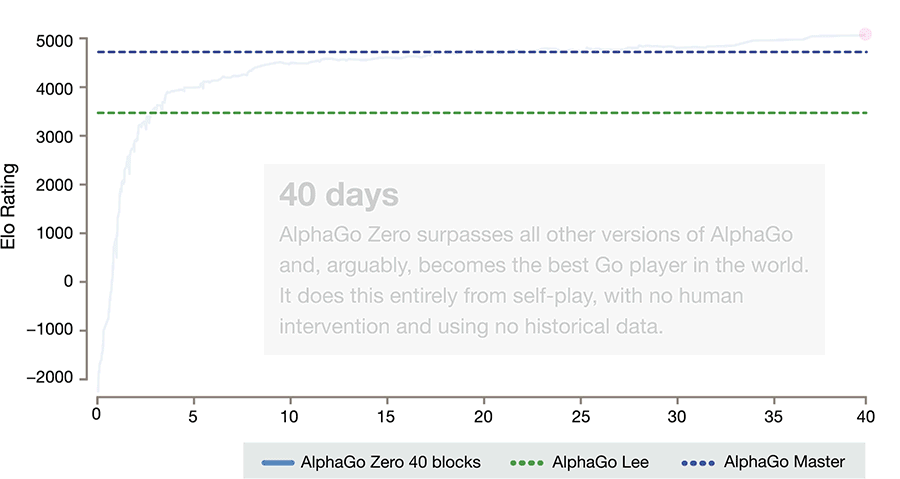
AlphaGo Zero skips this step and learns to play simply by playing games against itself, starting from completely random play. In doing so, it quickly surpassed human level of play and defeated the previously published champion-defeating version of AlphaGo by 100 games to 0.
and then I kept going and got to this point:
Quote:
It also differs from previous versions in other notable ways.
- AlphaGo Zero only uses the black and white stones from the Go board as its input, whereas previous versions of AlphaGo included a small number of hand-engineered features.
- It uses one neural network rather than two. Earlier versions of AlphaGo used a “policy network” to select the next move to play and a ”value network” to predict the winner of the game from each position. These are combined in AlphaGo Zero, allowing it to be trained and evaluated more efficiently.
- AlphaGo Zero does not use “rollouts” - fast, random games used by other Go programs to predict which player will win from the current board position. Instead, it relies on its high quality neural networks to evaluate positions.
Wow, this is so cool! I desperately hope they release self-play games from this version.
{kind=link}