I was not able to reproduce John's observed behaviour of LZ wanting to run out the ladder and expecting black to atari from on top using a recent LZ 247. I was however able to see something similar with the year-and-a-half old LZ 157 that comes with Lizzie 0.6 on low playouts. So I don't see anything mysterious here, just the well known problem of LZ with ladders on low playouts which are lessened in stronger more recent networks and ameliorated by giving more playouts.
To illustrate, here is 157's initial thoughts on ~300 total playouts, it wants to run out, and you can see mainline variation is for black to atari from on top, white takes a stone in gote and black reinforces the lower right and then white cuts and there's a fight. But bear in mind the first move only had 105 playouts so once you get several moves down the variation there are even fewer so these are mostly just playing on policy network instinct rather than much reading.
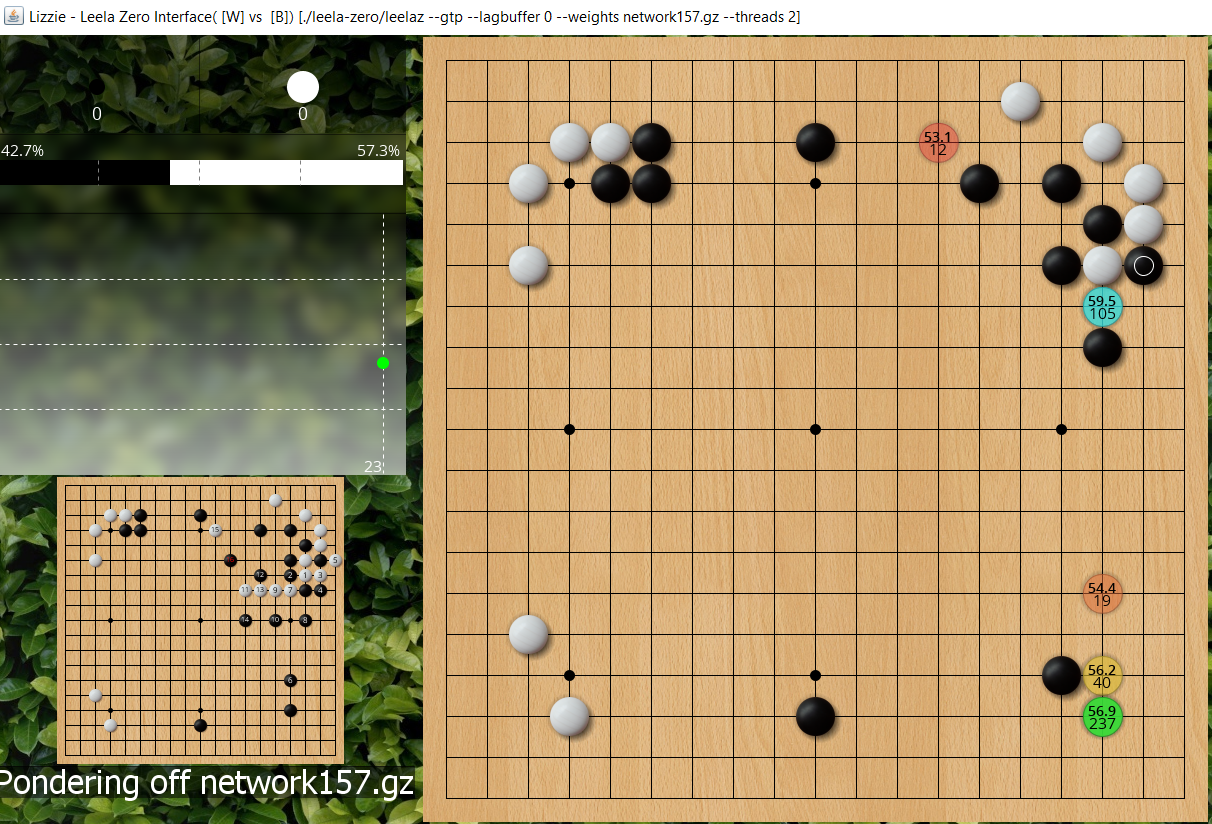
- jf ladder workshop1.PNG (1.45 MiB) Viewed 12198 times
Let LZ think a bit more (3k playouts) and now run out is not favoured, it wants to 3-3 invade at lower right, and is also looking at the attach I mentioned before as a promising blue circle move (lower playouts than #1 choice at 3-3, but higher winrate).
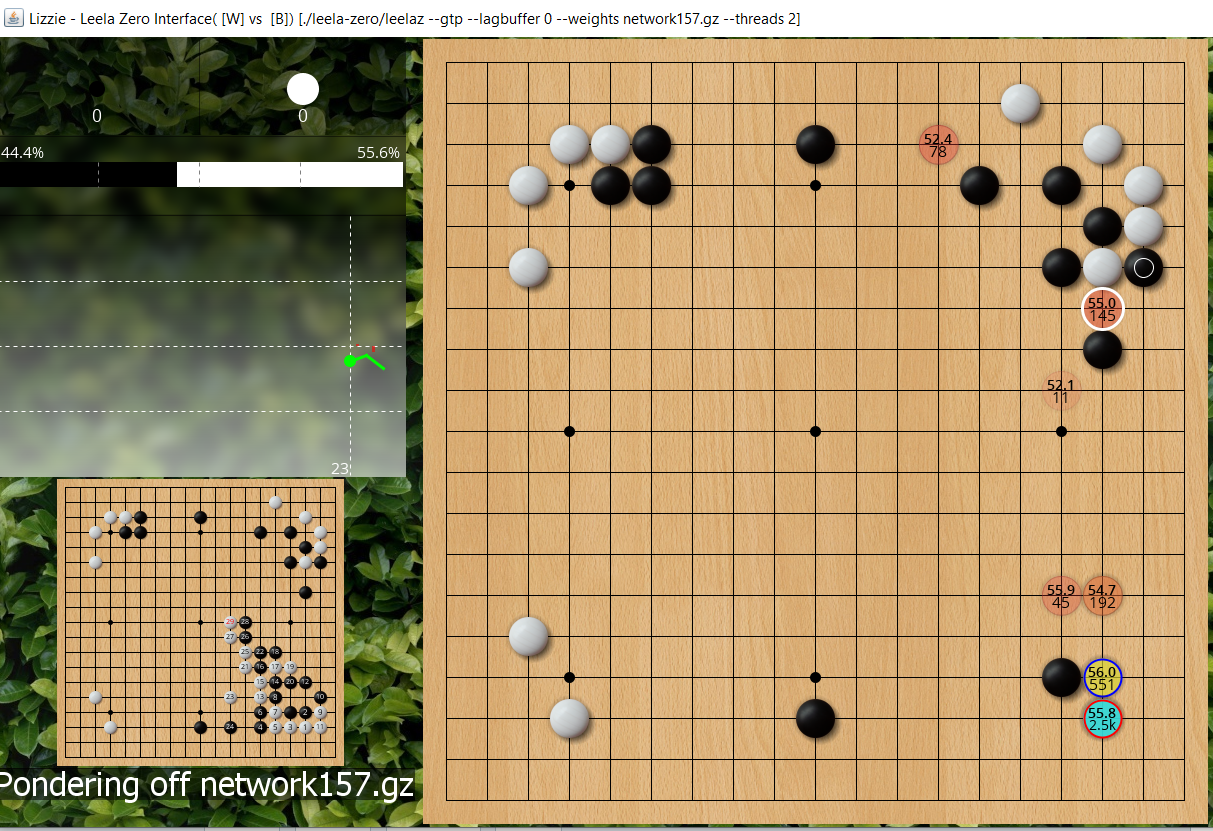
- jf ladder workshop2.PNG (1.47 MiB) Viewed 12198 times
What does it now think would happen if white runs out? Mouse over that move and we see that with only 209 playouts it now expects black to atari underneath and then white to tenuki and 3-3.
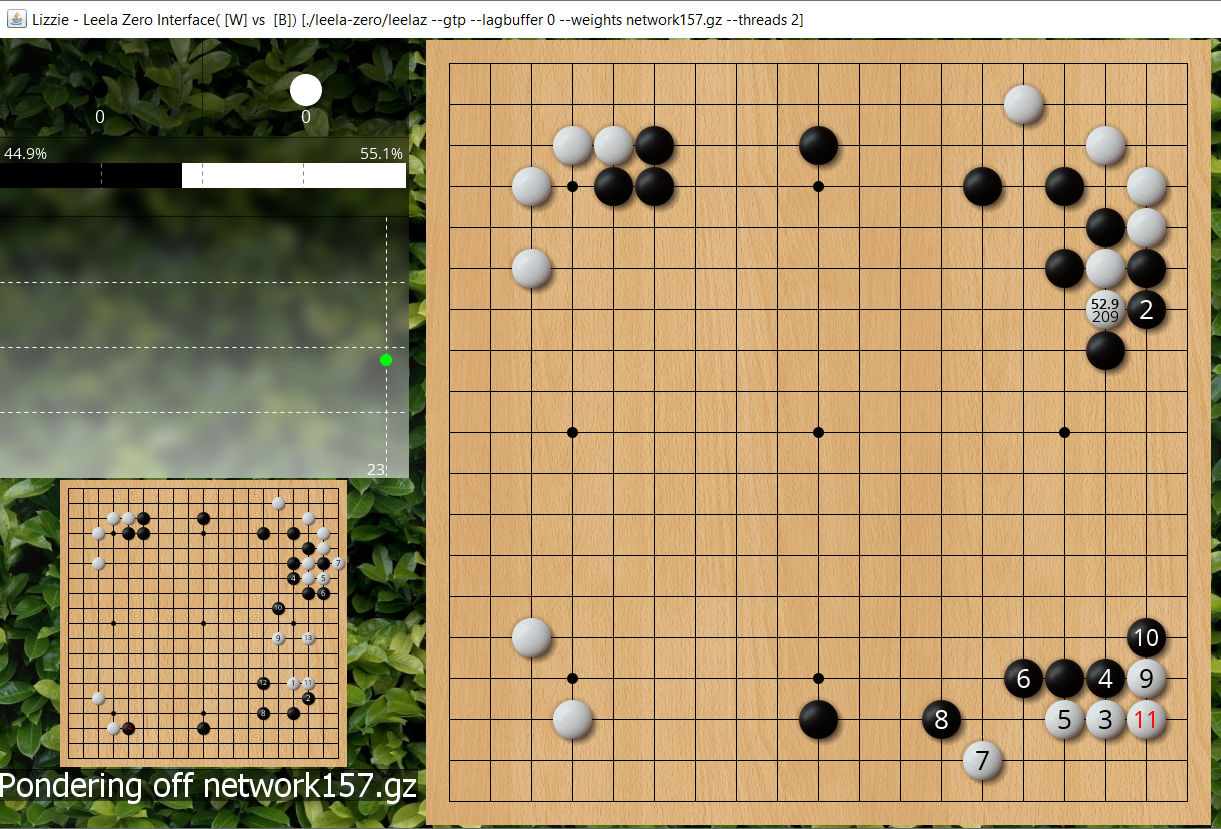
- jf ladder workshop2a.PNG (1.41 MiB) Viewed 12198 times
Does this mean it has realised the ladder works for black? That's easy to test, just play out the escape, atari under, escape, and what does it expect black to do? Answer is atari again, so yes it now has enough playouts to realise the ladder works for black. And we can see with each extra stone white is adding to the captured ladder black's winrate is increasing. This all makes sense.
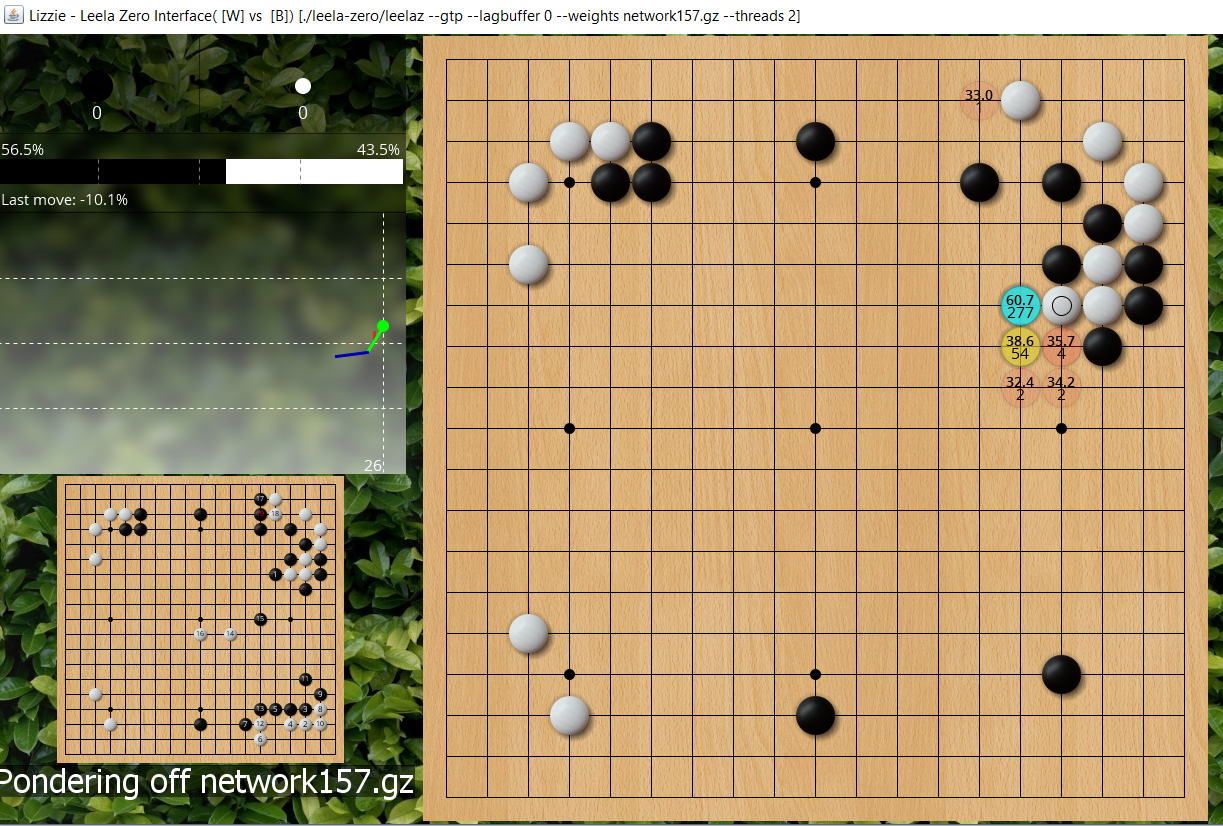
- jf ladder workshop2b.PNG (1.5 MiB) Viewed 12198 times
Give another thousand or two playouts and now that attachment is the blue move, note that more recent LZ engine as I'm using here no longer always picks the move with highest playouts as the first choice move, it's now a combination of playouts and winrate and this attachment already counts to LZ as the best move despite fewer playouts than 3-3.
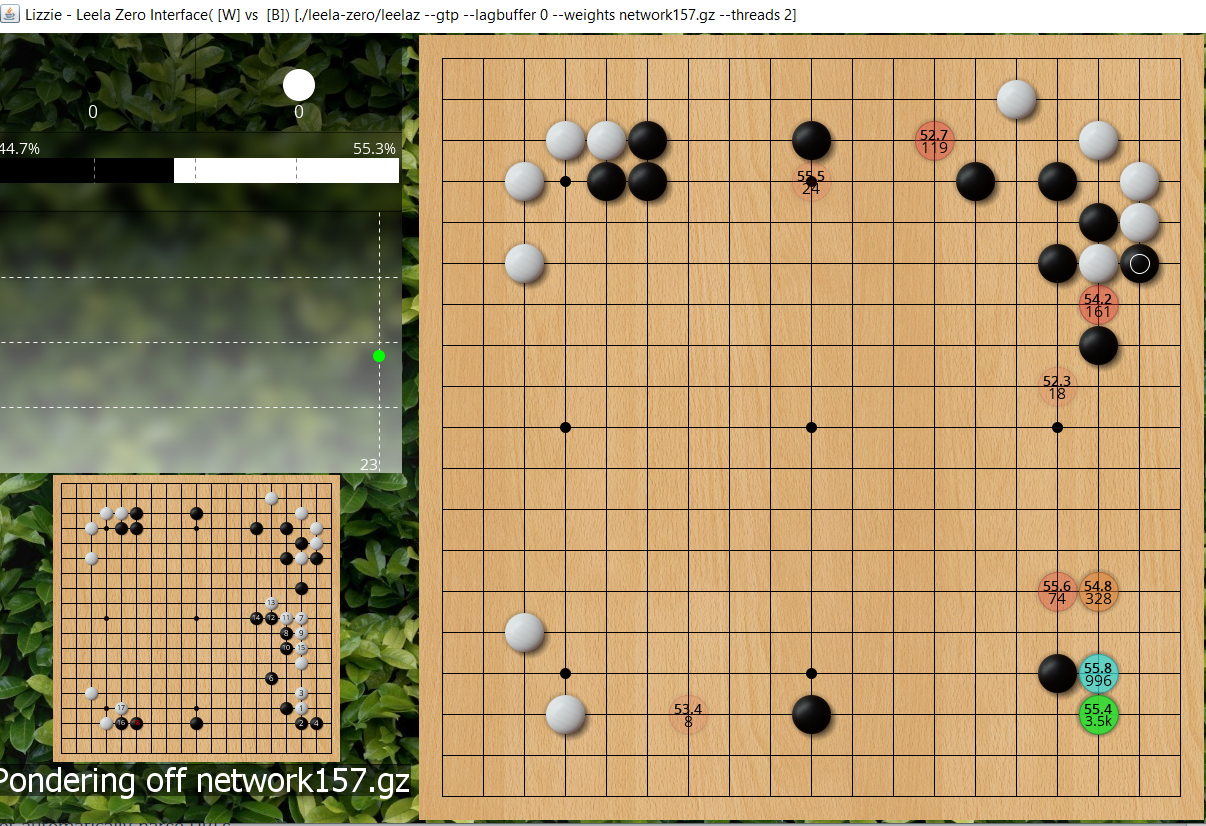
- jf ladder workshop3.PNG (1.46 MiB) Viewed 12198 times
Is there a point between my first and second diagram where LZ would want to run out, expects black to atari on top and then white would 3-3 like John saw? Maybe, but my computer is too fast for me to find it easily. But if it does happen, you don't need to just scratch your head and retreat into a fog of confusion. Did LZ think extend once and then tenuki to 3-3 was actually a good exchange/probe of testing if black wants to ladder and the take the 3-3, or was it just LZ not reading enough and deciding "oh well, take the stone in gote is bad, I'd better 3-3 now?" Play it out to test!
Extend once, if black atari on top and the 3-3 then with 15k playouts we see 157 thinks black is at 38.7%.
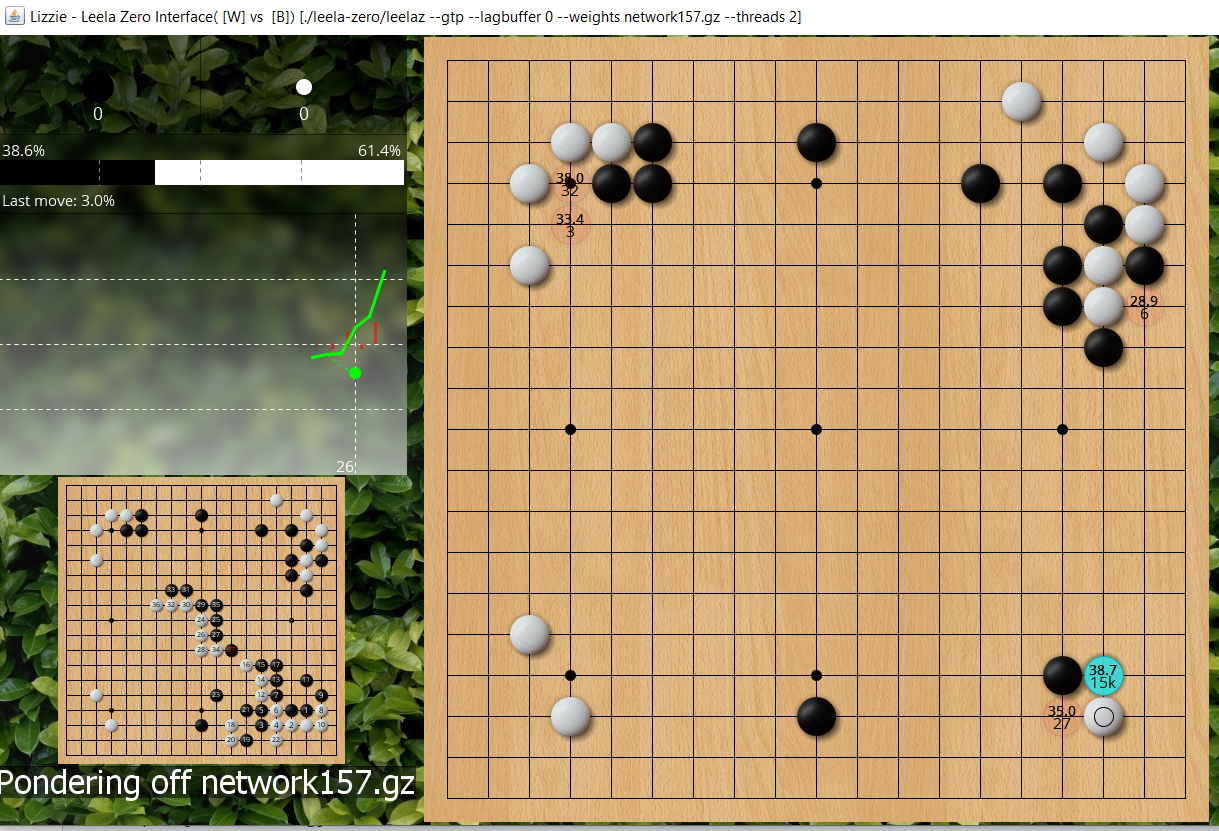
- jf ladder workshop4.PNG (1.49 MiB) Viewed 12195 times
If directly 3-3, then black is 45%, ie this is better for black than before, so it WAS good for white to run out if black will atari on top. This doesn't seem particularly mysterious to me, it makes sense as a probe so white has, in sente, created the option of saving the 2 stones which is a big move for territory and also leaves the cut afterwards.
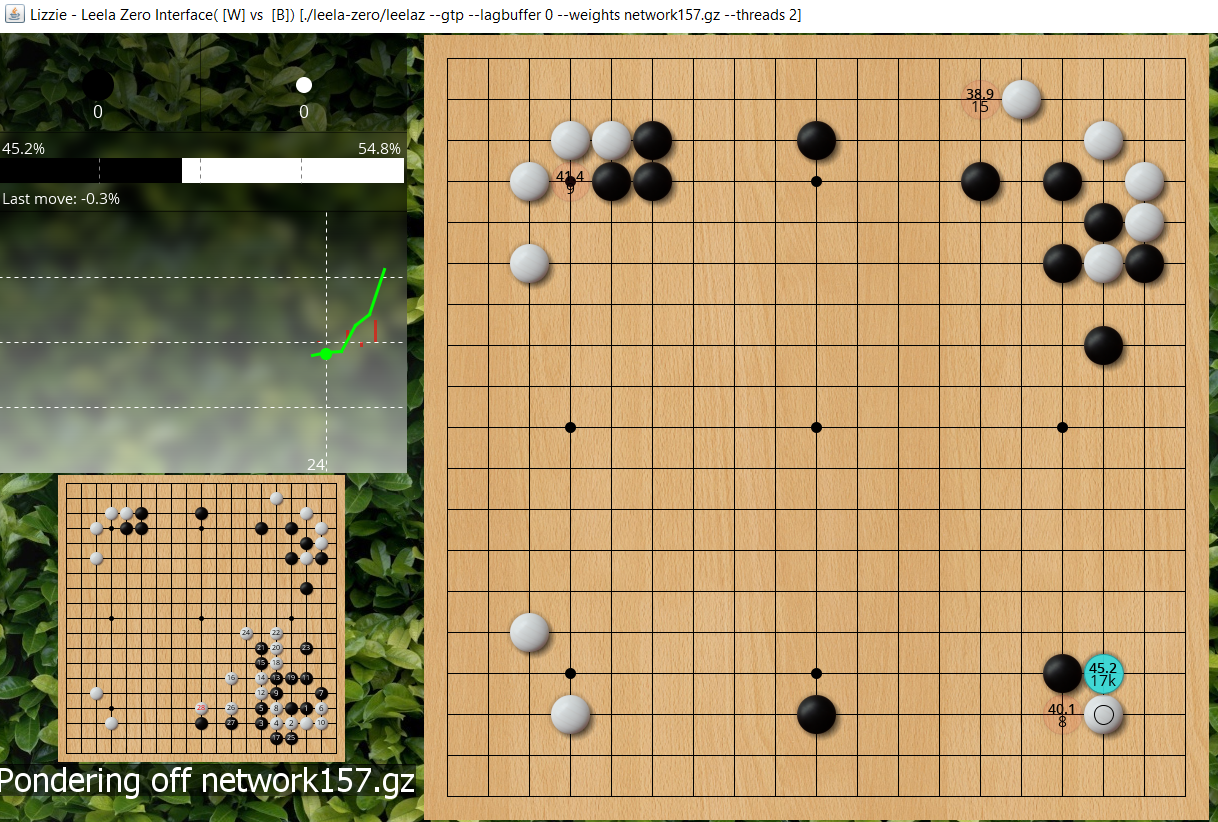
- jf ladder workshop5.PNG (1.47 MiB) Viewed 12195 times
But of course black may not atari on top, he could atari under as the ladder works. The downside of this is white gets a ladder breaker later. (Or if black answers it then white can run out the stones, which isn't an immediate disaster for black, but if that's going to happen he probably prefered to atari on top instead). We can ask LZ about this too. It says black is 47.5%, so this is the best for black, i.e. with enough playouts black would have atarid from below for ladder if white pulled out, because it doesn't want white to have the option of taking the 1 stone on edge.
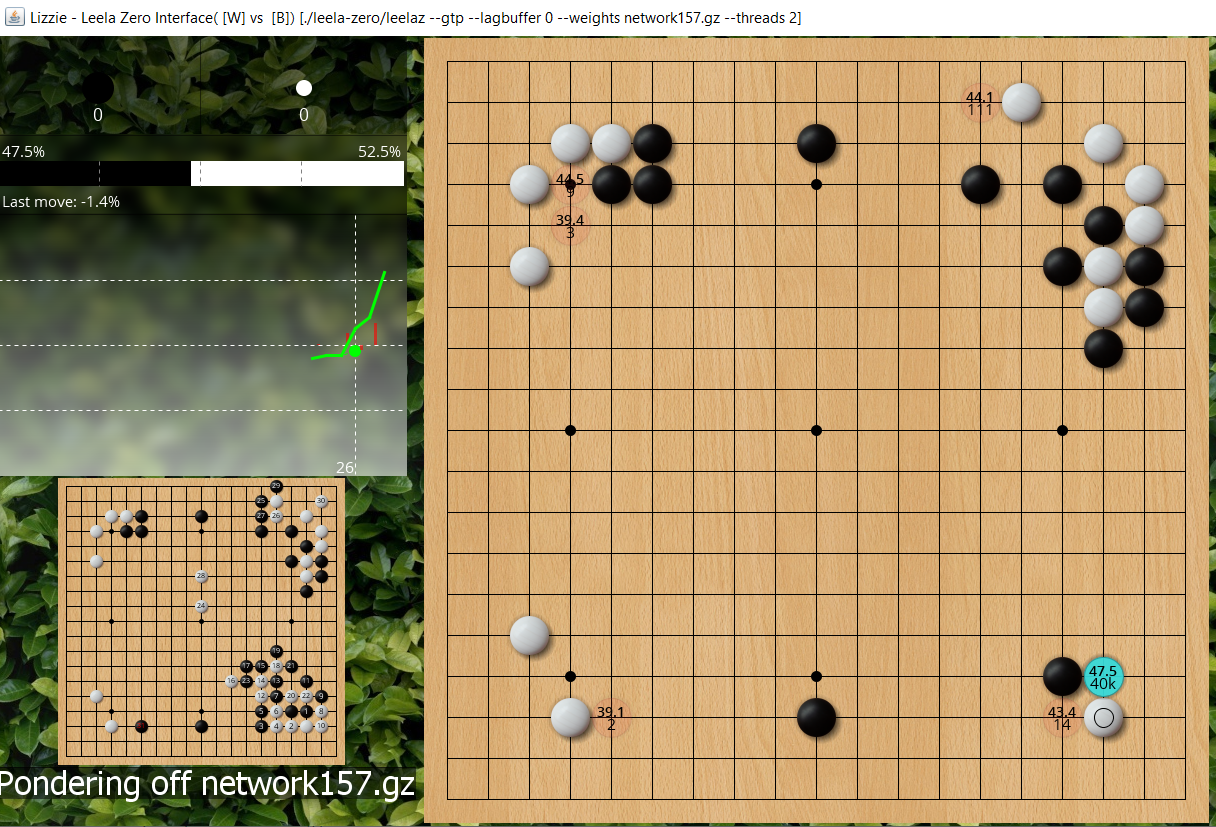
- jf ladder workshop6.PNG (1.48 MiB) Viewed 12195 times
I think the bookish theory would often not like pulling out the stone once and then tenuki, because if black spends the next move in the area he makes a tortoise-shell capture which is better for him than his 1 gote if white didn't pull out. However, to spend a move in that area is slow, so this is a case of thinking about local analysis leading you astray globally. We can see that LZ agrees it's a bad exchange for white if black answers correctly underneath (47% for black > 45), but it's a good exchange if white tricks black into playing the wrong answer of top atari ( 39% for black < 45). And because LZ 157 is bad at ladders at low playouts it falls for the trick initially. LZ 247 is better at ladders so it would not atari on top but atari under (or if it would atari on top it is for a much smaller window of low playouts which I didn't catch it in).
QED

